La fabrication du SI pose de nombreux problèmes aux développeurs dès que, et c’est toujours le cas, plusieurs équipes sont impliquées. Par exemple, une équipe pour développer le front, une pour le back. Et on ajoute une troisième, les utilisateurs qui testent le tout. Comment éviter que ces trois-là ne se fassent pas la guerre ? Le développement en parallèle n’est pas une nouveauté. Des solutions éprouvées existent. Comment les adapter à la fabrication du SI ? Comment, pratiquement, éviter de se gêner les uns les autres pendant le build et le run ?
Problème
Le front consomme des ressources produites par le back. Dans la phase de développement, les ressources évoluent très vite (jusqu’à plusieurs fois par jour) alors que les consommateurs ont besoin de stabilité. L’objectif est donc de proposer au front des ressources stables tout en permettant aux développeurs du back de les faire évoluer rapidement. En d’autres termes, il faut que chaque ressource exposée dispose de deux cycles de vie : celui des producteurs et celui des consommateurs.
Des solutions
Une solution simple pour proposer deux cycles de vie est de disposer de deux environnements de développement : un pour le front et un pour le back. La plateforme de fabrication distingue déjà deux environnements : les branches A et B. Il me semble difficile d’en introduire facilement d’autres. Par contre, il existe déjà un environnement justement prévu pour intégrer un consommateur et un producteur : la plateforme d’intégration.
La première piste consiste donc à utiliser la platefome d’intégration pour pousser les ressources en garantissant aux consommateurs une certaine stabilité. Le problème est résolu coté back (il est quand même nécessaire d’adopter les bonnes pratiques de gestions des sources, abordé dans un post ultérieur). Mais il est transféré coté front : comment, en DEV-TU, consommer des ressources de la platefome d’intégration ?
Une deuxième piste, permettant à tous de rester dans l’environnement DEV-TU, consiste à mettre à disposition des consommateurs une autre ressource, stable dans le temps : un bouchon. Là encore, il faut résoudre le problème « comment consommer ce bouchon ».
Avant de voir comment résoudre pratiquement l’utilisation d’une ressource différente (bouchon ou services déployés en intégration), il est important d’examiner comment les ressources sont consommées par le front (on se limitera au PUC pour l’instant).
Consommation des services SOA
Une UA consomme un service en utilisant un clieant SOAP : les classes Java générées par un plugin Eclipse. Le endpoint du service est configuré dans le fichier de contexte Spring (applicationContext.xml) :
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.0.xsd http://www.springframework.org/schema/mvc http://www.springframework.org/schema/mvc/spring-mvc-3.0.xsd">
<context:property-placeholder location="classpath:ua_rechercherdossiersinistre_version.properties" />
<bean id="ua_rechercherdossiersinistre.srvt_rechercherdossiersinistre" class="x.y.z.ihm.ws.WsConf">
<property name="serviceInterface" value="x.y.z.ihm.rechercherdossiersinistre.client.srvtrechercherdossiersinistre.generated.SRVTRechercherDossierSinistre" />
<property name="wsdlDocumentUrl" value="WEB-INF/wsdl/ua_rechercherdossiersinistre/SRVT_RechercherDossierSinistre/wsdl/SRVT_RechercherDossierSinistre.wsdl" />
<property name="namespaceUri" value="http://ca.cat.fr/df/Assurances/RechercherDossierSinistre/2/SRVT_RechercherDossierSinistre/" />
<property name="serviceName" value="SRVT_RechercherDossierSinistrePort" />
<property name="portName" value="SRVT_RechercherDossierSinistrePort" />
<property name="endpointAddress" value="${ua_rechercherdossiersinistre.service.srvtrechercherdossiersinistre.adresse}" />
</bean>
</beans>
Un proxy est ensuite utilisé pour obtenir le client (le framework ajoute certaines informations liées à la sécurité) :
WsConf wsConf = (WsConf) getBean("ua_rechercherdossiersinistre.srvt_rechercherdossiersinistre");
SRVTRechercherDossierSinistre srvtRechercherSini = getWsProxy(wsConf);
Jusqu’ici tout va bien : l’URL du endpoint est externalisée et le client du service est injecté. On peut donc espérer résoudre notre problème en spécifiant une URL particulière ou bien en injectant un autre bean qui simulera l’appel au service réel.
Consommation de services REST
todo (assez similaire à la consommation de services SOA)
Consommation de services intégration en DEV-TU
Pour rappel, nous allons faire en sorte que le client pointe sur le serveur d’intégration. Trivialement, on pourrait bien sur coder en dur l’URL dans le fichier de properties. Mais cela conviendrait à une règle importante : les sources ne sont pas modifiés en fonction de la cible de déploiement.
Maven et ses profils sont là pour ça.
L’URL du endpoint est externalisée dans le fichier ua_rechercherdossiersinistre_version.properties chargé par Spring :
ua_rechercherdossiersinistre.service.srvtrechercherdossiersinistre.adresse=${WSO2_MEDCHost}/${WSO2_adabo}/SRVT_RechercherDossierSinistre_vs_2
Les variables WSO2_MEDCHost et WSO2_adabo sont instanciées par les builders PIC selon la cible. Elles référencent le bus WSO2 (le médiateur). Pour pouvoir spécifier une URL spécifique pour un service (on ne change pas le bus), on va utiliser une autre variable :
ua_rechercherdossiersinistre.service.srvtrechercherdossiersinistre.adresse=${SRVT_RechercherDossierSinistre.endpoint}
Le pom.xml contient la valeur du endpoint :
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
...
<properties>
...
<SRVT_RechercherDossierSinistre.endpoint>${WSO2_MEDCHost}/${WSO2_adabo}/SRVT_RechercherDossierSinistre_vs_2</SRVT_RechercherDossierSinistre.endpoint>
</properties>
...
</project>
mvn pic:specialisation -P specialisation,local -DSRVT_RechercherDossierSinistre.endpoint="http://locahost:9080/SRVT_RechercherDossierSinistre"
On peut préférer ajouter un profil dans le pom :
<profiles>
<profile>
<id>pre-integration</id>
<activation>
<property>
<name>env</name>
<value>pre-integration</value>
</property>
</activation>
<properties>
<SRVT_RechercherDossierSinistre.endpoint>http://slzuys6wso03.yres.ytech:19204/${WSO2_adabo}/SRVT_RechercherDossierSinistre_vs_2</SRVT_RechercherDossierSinistre.endpoint>
</properties>
</profile>
</profiles>
Le host de l’URL du service est défini avec le médiateur de l’environnement d’intégration (le site phisio donne les serveurs de chaque environnement).
Le profil est activé en définissant la propriété env à la valeur pre-integration` :
mvn pic:specialisation -P specialisation,local -Denv=pre-integration
Pour le build sur la plateforme DEV-TU effectué par la PIC, il faudra définir la propriété dans la définition de la génération demandée :
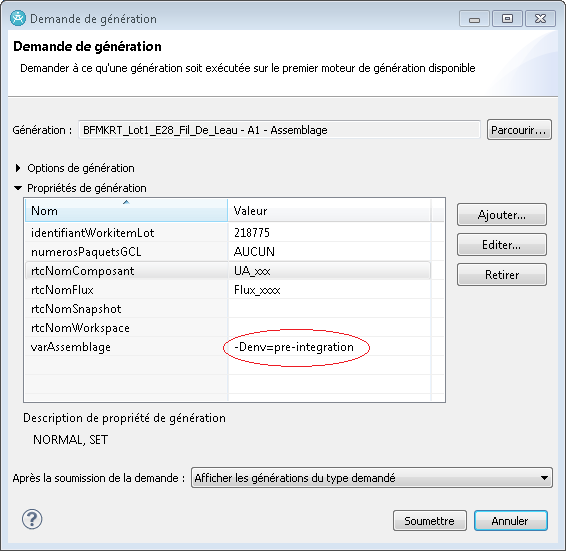
Simulation des services
L’autre moyen de garantir la stabilité du service est de simuler les appels. Nous allons donc remplacer le service réel par un fake.
Le client du service est instancié comme suit :
WsConf wsConf = (WsConf) getBean("ua_rechercherdossiersinistre.srvt_rechercherdossiersinistre");
SRVTRechercherDossierSinistre srvtRechercherSini = getWsProxy(wsConf);
Le bean wsConf est un POJO définissant les informations du services (le endpoint, la classe d’interface). Il sera également utilisé par le service fake.
L’obtention du proxy est plus problématique : la méthode est protected et finale. C’est normal. Les concepteurs adressent un message clair aux développeurs : ne surchargez pas cette méthode, en cas de modification, cela risque de ne plus marcher. Soit. On devrait stopper ici mais, un changement impose de faire évoluer le framework ET que le projet intègre cette modification (changement de la version de la dépendance). Donc si la méthode getWsProxy évolue, le projet ne sera impacté que s’il le décide. Bref, nous allons contourner l’interdiction.
Le code cette méthode est le suivant :
protected final <T> T getWsProxy(WsConf wsConf)
throws TechnicalException
{
return (T)WsProxyFactory.getWsProxy(wsConf, getContext(), getUaID(), getUaVersion());
}
La méthode getWsProxy de la classe WsProxyFactory est publique. Les arguments qui lui sont passés sont, en plus de la configuration du WS, des informations liées au controler implémenté par l’UA. Nous pouvons la ré-écrire :
package x.y.z.ihm.rechercherdossiersinistre.utils;
import x.y.z.ihm.catalog.tools.Version;
import x.y.z.ihm.controller.bean.Context;
import x.y.z.ihm.exception.TechnicalException;
import x.y.z.ihm.ws.WsConf;
import x.y.z.ihm.ws.WsProxyFactory;
public class WsProxyManager {
@SuppressWarnings("unchecked")
public <T> T getWsProxy(WsConf wsConf, Context context, String uaId, Version uaVersion) throws TechnicalException {
return (T) WsProxyFactory.getWsProxy(wsConf, context, uaId,
uaVersion);
}
}
et changer l’appel :
WsProxyManager proxyMgr = (WsProxyManager) getBean("WsProxyManager");
SRVTRechercherDossierSinistre srvtRechercherSini =
proxyMgr.getWsProxy(wsConf, getContext(), getUaID(), getUaVersion());
Le bean WsProxyManager est déclaré dans le contexte :
<bean id="WsProxyManager" class="x.y.z.WsProxyManager" />
Nous avons maintenant la base pour pourvoir fournir un fake service en changeant l’implémentation de WsProxyManager :
public class FakeWsProxyManager {
@SuppressWarnings("unchecked")
public <T> T getWsProxy(WsConf wsConf, Context context, String uaId, Version uaVersion) throws TechnicalException {
if (wsConf.getServiceInterface().isAssignableFrom(SRVTRechercherDossierSinistre.class)) {
return (T) new SRVTRechercherDossierSinistreFake();
}
return (T) WsProxyFactory.getWsProxy(wsConf, context, uaId,
uaVersion);
}
}
FakeWsProxyManager permet de fournir la classe de simulation pour le client SRVTRechercherDossierSinistre. Cette classe implémente l’interface du service et créera des données de la façon la plus appropriée (codées en dur, générées aléatoirement, lues depuis un fichier de configuration, dans une base embarquée, etc.)
Reste à essayer de régler un problème : nos bonnes pratiques voudraient que le build “cible” (pour l’intégration et au delà) produise les binaires et la configuration prévus pour cette cible. On ne doit pas risquer de déployer en intégration une UA qui utiliserait un fake.
On pourrait s’appuyer les profils Spring (introduits en 3.1). Mais ces derniers sont activables à l’exécution. Je ne sais pas s’il est possible de faire ajouter une option dans les serveurs WAS en DEV-TU. Le build doit donc résoudre ce problème. Les profils maven vont encore une fois nous aider.
Ce que nous devons faire c’est changer l’implémentation du bean WsProxyManger en fonction du profile choisi. Commençons par ajouter dans le pom une propriété référençant la classe d’implémentation :
...
<properties>
...
<SRVT_RechercherDossierSinistre.WsProxyManager>x.y.z.WsProxyManager</SRVT_RechercherDossierSinistre.WsProxyManager>
</properties>
...
</project>
Cette variable référence la classe immplémentant le proxy cible. On ajoute ensuite un profil qui va permettre de remplacer cette implémentation par un fake :
<profiles>
<profile>
<id>pre-integration</id>
<activation>
<property>
<name>env</name>
<value>pre-integration</value>
</property>
</activation>
<properties>
...
<SRVT_RechercherDossierSinistre.WsProxyManager>x.y.z.FakeWsProxyManager</SRVT_RechercherDossierSinistre.WsProxyManager>
</properties>
</profile>
</profiles>
Le profil est activé en définissant la propriété env à la valeur pre-integration` :
mvn pic:specialisation -P specialisation,local -Denv=pre-integration
Voili voila !
Conclusion
Nous avons deux solutions pour que les développeurs du front vivent leur vie sans gêner ceux du back. Ils peuvent consommer les services déployés en intégration ou bien utiliser les fakes. La première solution présente l’avantage de n’avoir rien à développer alors qu’il faut développer du code pour simuler les données dans la deuxième solution. Ceci-dit, développer un bouchon devrait être la première chose faite, indépendamment du partage de responsabilité. Cela peut paraitre fastidieux mais cela fait gagner du temps par la suite. Reste une question : qui est responsable du bouchon : le front ou le back ? Idéalement, les deux. C’est le back qui doit proposer un bouchon mais le front doit pouvoir l’adapter à ses use cases. La responsabilité doit être partagée. En plus cela permet aux deux équipes de se parler et de mieux se comprendre.